An idea has been in the works for the past three years that is core to Yaak's belief; Given country-scale datasets and scalable architectures, end-to-end ML models outperform rules-based systems at scoring safe driving. We've worked hard to scale our customer fleet, and source the gold standard of safe driving data in order to realize our vision. Our customer fleet provides us with two complementary data sources: expert driving demonstrations, and driving mistakes. As we'll discuss below, scaling both these data sources was necessary to realize SafetyAI. At the intersection of imitation learning and large language models, SafetyAI is an annotation-free (no bounding boxes, segmentation masks), world-model-based causal transformer.
As a society, we’ve grounded the rules of the road in driver training, traffic signs, and laws, but at times they are overlooked leading to dangerous scenarios. What decisions would a seasoned driving expert make in these safety-critical situations? Imagine a tool that could accurately generate those decisions. Welcome SafetyAI, which estimates optimal vehicle control based on the surrounding environment. From slowing down at a yield sign to successfully merging onto a highway, SafetyAI does it all — and without any reliance on labeled bounding boxes, segmentation maps, or traffic sign information.

SafetyAI relies on OpenStreetMap (right) instead of labeled object masks and HD maps (left).
Autoregressive models
SafetyAI is a fully-realized, multi-modal, generative AI trained with expert demonstrations, and designed to be aligned with instructor evaluations. The experts (driving instructors) log their demonstrations — captured via our omni-directional camera rig and vehicle gateway — on complex routes known for high rates of driving errors.

Map of Freiburg, Germany with driven routes, and logged driving mistakes.
On the same routes, instructors also evaluate student driving based on specific lesson topics from parking procedures [1] to multi-lane-change exits on the highway [2]. The evaluations form an important sparse signal for SafetyAI to align itself with these topics.

[1] Parallel parking procedure

[2] Multi-lane change and exit on highway
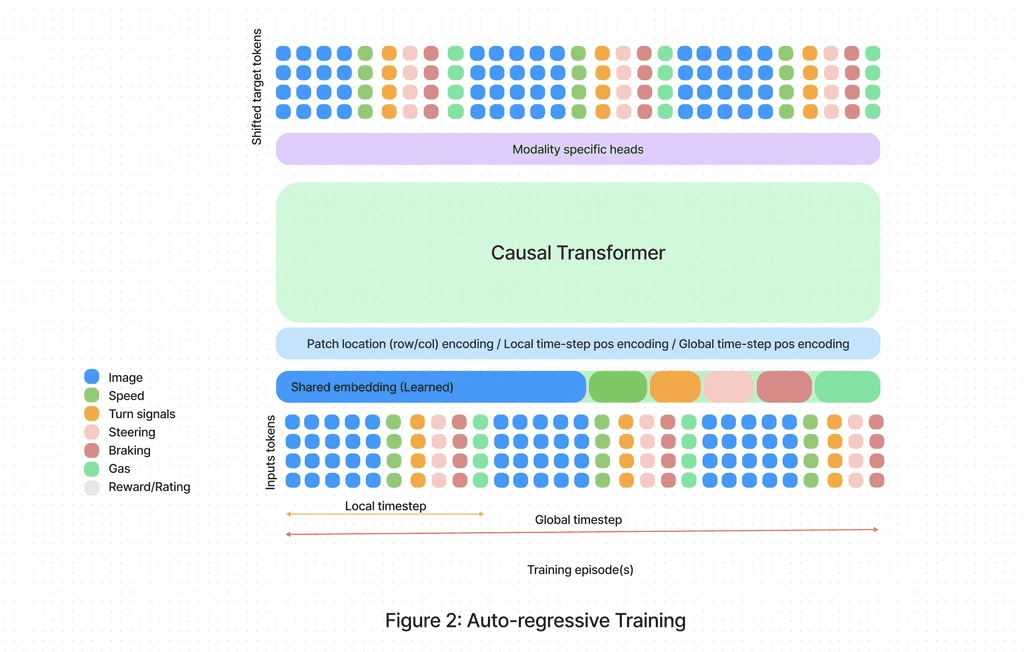
Built from these two data sources, SafetyAI employs autoregressive training to forecast future states of the vehicle (camera frames), as well as a distribution over vehicle controls through teach forcing.
Pixels & vehicle metadata
For our SafetyAI, the data from its cameras and other sensors, including metadata, are subjected to distinct translation processes — what we call 'tokenization pipelines.' For camera data, we've pre-trained a discrete, variational auto-encoder (VQ-VAE), and taught a visual codebook. Each entry or token in the visual codebook corresponds to a learned embedding. During training, we update the codebook and model to minimize the difference between the input frame (left) and the frame reconstructed from tokens (right).

Left: Input image. Middle: Image tokens from codebook. Right: Reconstructed image.


Left: Original, 360k floats (32 bits). Right: Reconstructed, 1k integers (16 bits).
After training the VQ-VAE, representing images with tokens from the visual codebook — rather than pixels — reduces the information SafetyAI has to learn from by a factor of 100x. This makes it more data-efficient, and speeds up the training for SafetyAI. For sensor metadata tokenization, we've adapted a tried-and-true method from audio processing: mu-law encoding. Applied to sensor measurements and controls (gas, braking, steering), this method offers adaptive binning for signals close to zero, which is true for steering (driving straight) and braking.

Pixels & vehicle metadata
We employ imitation learning as a conditional, sequence-modeling paradigm to train SafetyAI with expert data from our driving school fleet (instructors). Imitation learning is modeled via a causal transformer, which is a GPT-like architecture offering the versatility of scalable architectures. The model is trained to predict the next token (image/metadata/action or reward) given the historical vehicle context, as shown in the figure below. We use a historical context window of three seconds for training.

Naively training SafetyAI with tokenized historical data is suboptimal since the model can simply 'interpolate', or 'cheat', from the previous metadata/action input (expert actions are highly co-related to past actions). This we explain in the next section.
Overcoming causal confounders
One challenge with training SafetyAI on temporal data is the occurrence of causal confusion. This is due to the fact that the action tokens the model is trying to predict at the next step are often part of the vehicle history, so the models can simply cheat, and find a shortcut to predict them. For example, during training the model learns to predict braking only if braking is part of its input, and thus never learns to pick up visual cues (e.g. objects, signs, lights) to stop.

During training, the model has to predict if the vehicle is braking at t+5: ?. Since braking is part of the model's historical vehicle context, the model can simply cheat, and learn to predict braking only when it sees braking in the model's historical, vehicle-context input.
This is far from ideal, since our objective for SafetyAI is to identify dangerous scenarios and suggest preemptive measures (such as braking). To address this, we employ a strategy of masking the tokens that are associated with causal confusion from the vehicle's historical data. This method diminishes the impact of causal confounders, encouraging the model to learn from visual indicators (e.g. traffic lights, signs) that prompted the expert to execute a specific action (steer right or slam instructor pedals).

Different masking strategies: Confounder dropout works best since it forces prediction of the braking token at every time-step — except the last — to focus on the visual cues in pixels.

The model's predictions are shown in green, while the ground truth (GT) trajectory is in red. Without masking, the AI is allowed to cheat by looking at actions in the past, leading to inaccurate predictions as seen in the video on the left (predicting braking only when vehicle starts braking). The video on the right, however, shows the use of masking, and how it results in correct predictions (preemptive braking).
Rating Model
As a second step, following the widely adopted paradigm of RLHF, we tune SafetyAI to align with the preferences of driving instructors through a rating/reward model. This model ranks and scores student driving, (1) with supervision provided via labeled incidents, and (2) student ratings logged during driving lessons.

Rating/reward model trained on instructor feedback during on-road student driving lessons.
As the final step, we use the rating/reward model to tweak SafetyAI. This helps SafetyAI become better at evaluating safe driving through alignment.
Driving instructor alignment
While the reward model is essential, it alone isn't enough to enhance the workflow of driving experts. This is because, in addition to evaluating students' driving skills, instructors also provide correction and guidance. This is where the generative aspect of SafetyAI excels, as it can suggest optimal driving policies that maximize rewards when a student's driving is flagged by either SafetyAI or instructors.

Tuning causal transformer to generate vehicle controls that maximize the reward model output.
Internal world model

Reconstructing future frames with causal transformer
Below, are three visuals representing future states based on previous actions and frames.

The first three frames are the model prompt, while the last three frames have been generated by SafetyAI. These road segments have never been seen by SafetyAI.
The world model is a powerful tool to mitigate the impact of out-of-distribution scenes that SafetyAI might encounter in the wild. We realized this by bridging popular text-to-image generation models and the world model in SafetyAI. We call this ‘prompt attacks.’
Prompt attacks
Prompt attacking involves editing the input data stream to SafetyAI using state-of-the-art, prompt-enabled image editing. This powerful method allows us to prepare the system for a broader range of driving scenarios by letting SafetyAI imagine a future with the prompt attacks, and then have it show us how to safely navigate them.
We're excited to announce our plans to make our prompt attack portal available to the public. Prioritizing instructors and students initially, we aim to enhance the development of SafetyAI. This platform will allow anyone, from anywhere in the world, to add or modify a scene with prompts. They can then review the future frames and actions that SafetyAI generates in response to these prompts, contributing to the continuous improvement and adaptation of our AI system.
the road ahead
SafetyAI and the Yaak platform is built with scalability in mind, as well as the ability to robustly score safety with high accuracy, and without knowing the road segment or driving scenario in advance. In our upcoming blog posts, we will dive deeper into how we further enhanced SafetyAI's performance by incorporating pre-existing knowledge about scene dynamics (e.g. depth, auto-calibration of multiple sensors) into SafetyAI's training. This approach is more efficient than starting from scratch, and contributes to a more refined system.
We will also explore the new data modalities we plan to extract from driving lessons and exams, as well as how we plan to improve the natural feedback loop we established with our growing network of local experts.
We look forward to sharing more about these exciting developments in our upcoming blog posts. Stay tuned!