Yaak & Lerobot team · March 11, 2025
State-of-the art Vision Language Models and Large Language Models are trained on open-source image-text corpora sourced from the internet, which spearheaded the recent acceleration of open-source AI. Despite these breakthroughs, the adoption of end-to-end AI within the robotics and automotive community remains low, primarily due to a lack of high quality, large scale multimodal datasets like OXE. To unlock the potential for robotics AI, Yaak teamed up with the LeRobot team at 🤗 and is excited to announce Learning to Drive (L2D) to the robotics AI community. L2D is the world’s largest multimodal dataset aimed at building an open-sourced spatial intelligence for the automotive domain with first class support for 🤗’s LeRobot training pipeline and models. Drawing inspiration from the best practices of source version control, Yaak also invites the AI community to search and discover novel episodes in our entire dataset (> 1 PetaBytes), and queue their collection for review to be merged into future release (R5+).
Dataset
Observation
State
Actions
Task/Instructions
Episodes
Duration (hr)
Size TB
L2D (R4)
RBG (6x)
GPS/IMU/CAN
☑️
☑️
1M
5,000+
90+
Table 1: Open source self-driving datasets. (Source)
L2D was collected with identical sensor suites installed on 60 EVs operated by driving schools in 30 German cities over the span of 3 years. The policies in L2D are divided into two groups — expert policies executed by driving instructors and student policies by learner drivers. Both the policy groups include natural language instruction of the task as context: For example, “When you have the right of way, take the third exit from the roundabout, carefully driving over the pedestrian crossing”.
Expert policy—Driving instructor


Fig 1: 3 of 6 cameras in L2D shown here for clarity, Visualization: Nutron.
Task: “When you have the right of way, drive through the roundabout and take the third exit”.
Expert policies have zero driving mistakes and are considered as optimal, whereas student policies have known sub optimality (Fig 2).

Fig 2: Student policy with jerky steering to prevent going into lane of the incoming truck
Both groups cover all driving scenarios that are mandatory for completion to obtain a driving license within the EU (German version), for example, overtaking, roundabouts and train tracks. In the release (See below R3+), for suboptimal student policies, a natural language reasoning for sub-optimality will be included.

Expert: Driving Instructor
Expert policies are collected when driving instructors are operating the vehicle. The driving instructors have at least 10K+ hours of experience in teaching learner drivers. The expert policies group covers the same driving tasks as the student policies group.

Student: Learner driver
Student policies are collected when learner drivers are operating the vehicle. Learner drivers have varying degrees of experience (10 - 50 hours). By design, learner drivers cover all EU mandated driving tasks, from high speed lane changes on highways to navigating narrow pedestrian zones.
l2d: Learning to drive
L2D (R2+) aims to be the largest open-source self-driving dataset that empowers the AI community with unique and diverse ‘episodes’ for training end-to-end spatial intelligence. With the inclusion of a full spectrum of driving policies (student and experts), L2D captures the intricacies of safely operating a vehicle. To fully represent an operational self-driving fleet, we include episodes with diverse environment conditions, sensor failures, construction zones and non-functioning traffic signals.
Both the expert and student policy groups are captured with the identical sensor setup detailed in the table below. Six RGB cameras capture the vehicle’s context in 360o, and on-board GPS captures the vehicle location and heading. An IMU collects the vehicle dynamics, and we read speed, gas/brake pedal, steering angle, turn signal and gear from the vehicle’s CAN interface. We synchronized all modality types with the front left camera (observation.images.front_left) using their respective unix epoch timestamps. We also interpolated data points where feasible to enhance precision (See Table 1.) and finally reduced the sampling rate to 10 hz.

Fig 3: Multimodal data visualization with Nutron (only 3 of 6 cameras shown for clarity)
Modality
LeRobotDataset v2.1 key
Shape
alignment[tol][strategy]
Table 2: Modality types, LeRobot v2.1 key, shape and interpolation strategy.
L2D follows the official German driving task catalog (detailed version) definition of driving tasks, driving sub-tasks and task definition. We assign a unique Task ID and a natural language description of the context to all episodes. The task (LeRobot:task) for all episodes is set to “Follow the waypoints adhering to driving rules and regulations”. The table below shows a few sample episodes, their natural language instruction (context), driving tasks and subtasks. Both expert and student policies have an identical Task ID for similar scenarios, whereas the context varies with the episode.
Episode
Instructions
Driving task
Driving sub-task
Task definition
Task ID
Drive straight through going around the parked delivery truck and yield to the incoming traffic
3 Passing, overtaking
3.1 Passing obstacles and narrow spots
This sub-task involves passing obstacles or navigating narrow roads while following priority rules.
3.1.1.3a Priority regulation without traffic signs (standard)
Drive through the unprotected left turn yielding to through traffic
4 Intersections, junctions, entering moving traffic
4.1 Crossing intersections & junctions
This sub-task involves crossing intersections and junctions while following priority rules and observing other traffic.
4.3.1.3c With traffic lights
Drive up to the yield sign and make the unprotected left turn while yielding to bike/pedestrian and vehicle
4 Intersections, junctions, entering moving traffic
4.3 Left turns at intersections & junctions
This sub-task involves making left turns at intersections while observing traffic signals and yielding appropriately.
4.3.1.3c With traffic lights
Table 3: Sample episodes in L2D, their context and Task ID derived from EU driving task catalog
We automate the construction of the instructions and waypoints using the vehicle position (GPS), Open-Source Routing Machine, OpenStreetMap and a Large Language Model (LLM) (See below). The natural language queries are constructed to closely follow the turn-by-turn navigation available in most GPS navigation devices. The waypoints (Fig 4) are computed by map-matching the raw GPS trace to the OSM graph and sampling 10 equidistant points (orange) spanning 100 meters from the vehicles current location (green), and serve as drive-by-waypoints.

Fig 4: L2D 6x RGB cameras, waypoints (orange) and vehicle location (green)
Context: “drive straight up to the stop stop sign and then when you have right of way, merge with the moving traffic from the left”
search & Curation
Expert policies
GPS traces from the export policies collected from the driving school fleet. Click here to see the full extent of expert policies in L2D

Student policies
Student policies cover the same geographical locations as expert policies. Click here to see the full extent of student policies in L2D.
We collected the expert and student policies with a fleet of 60 KIA E-niro driving school vehicles operating in 30 German cities, with an identical sensor suite. The multimodal logs collected with the fleet are unstructured and void of any task or context information. To search and curate for episodes we enrich the raw multimodal logs with information extracted through map matching the GPS traces with OSRM and assigning node and way tags from OSM (See next section). Coupled with a LLM, this enrichment step enables searching for episodes through the natural language description of the task.
openstreetmap
For efficiently searching relevant episodes, we enrich the GPS traces with turn information obtained by map-matching the traces using OSRM. We additionally use the map-matched route and assign route features, route restrictions and route maneuvers, collectively referred to as route tasks, to the trajectory using OSM (See sample Map). Appendix A1-A2 provides for more details on the route tasks we assign to GPS traces.

Fig 5: Tasks assigned to raw GPS trace (map view)
The route tasks which get assigned to the map-matched route, are assigned the beginning and end timestamps (unix epoc), which equates to the time when the vehicle enters and exits the geospatial linestring or point defined by the task (Fig 6).

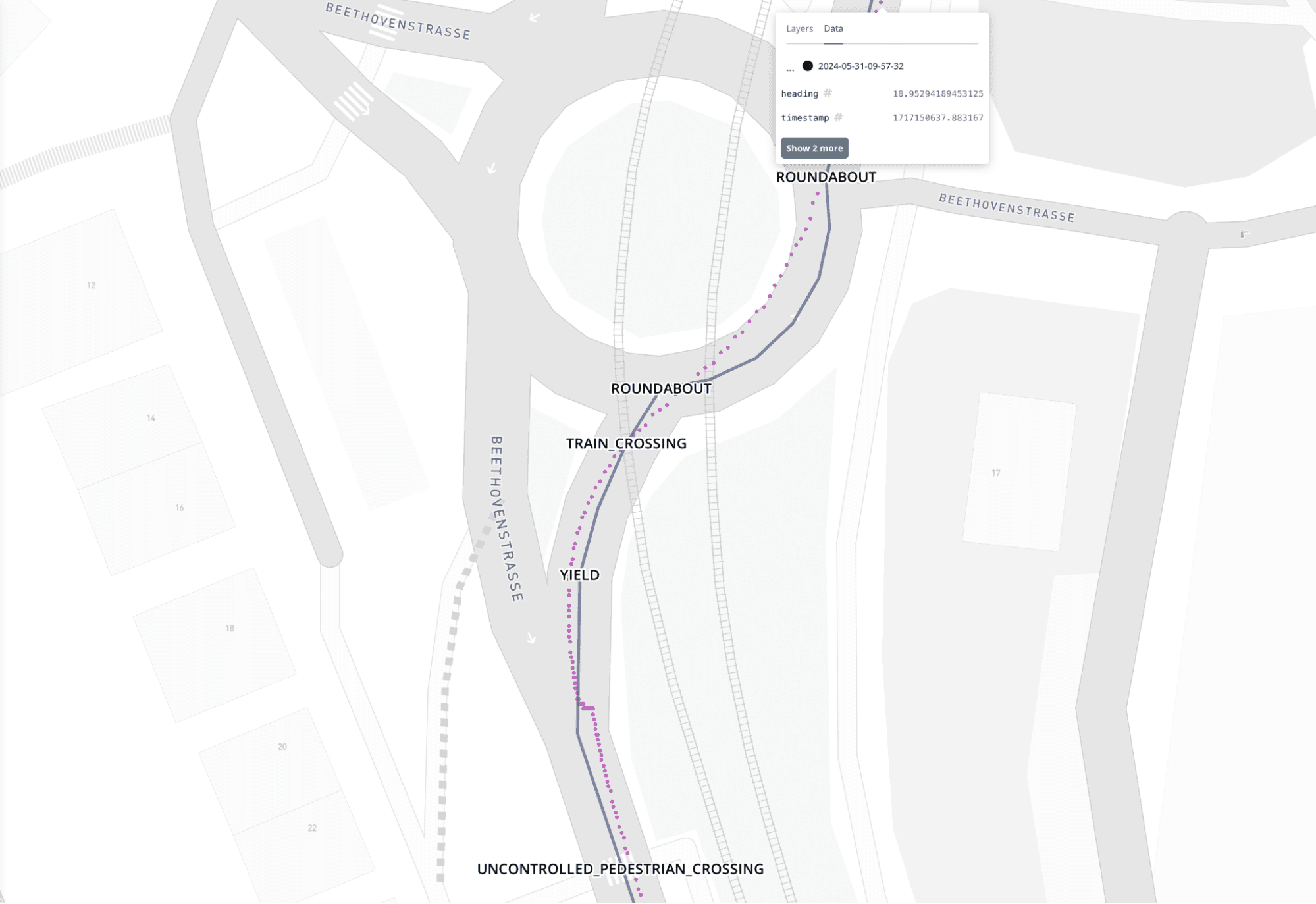
Fig 6: Pink: GNSS trace, Blue: Matched route, tasks: Yield, Train crossing and Roundabout (map view)
multimodal search
We perform semantic spatiotemporal indexing of our multimodal data with the route tasks as described in Fig 5. This step provides a rich semantic overview of our multimodal data. To search within the semantic space for representative episodes by context, for example, “drive up to the yield sign, and then over the train crossing and through the roundabout”, we built a LLM-powered multimodal natural language search, to search within all our drive data (> 1 PB) and retrieve matching episodes.
We structured the natural language queries (context) to closely resemble turn-by-turn navigation available in GPS navigation devices. To translate context to route tasks, we prompt the LLM with the query and steer its output to a list of route features, route restrictions, route maneuvers and retrieve episodes assigned to these route tasks. We perform a strict validation of the output from the LLM with a pydantic model to minimize hallucinations. Specifically we use llama-3.3-70b and steer the output to the schema defined by the pydantic model. To further improve the quality of the structured output, we used approx 30 pairs of known natural language queries and route tasks for in-context learning. Appendix A.2 provides details on the in-context learning pairs we used.

lerobot
L2D on 🤗 is converted to LeRobotDataset v2.1 format to fully leverage the current and future models supported within LeRobot. The AI community can now build end-to-end self-driving models leveraging the state-of-the-art imitation learning and reinforcement learning models for real world robotics like ACT, Diffusion Policy, and Pi0.
Existing self-driving datasets (table below) focus on intermediate perception and planning tasks like 2D/3D object detection, tracking, segmentation and motion planning, which require high quality annotations making them difficult to scale. Instead L2D is focused on the development of end-to-end AI which learns to predict actions (policy) directly from sensor input (Table 1.). These models leverage internet pre-trained VLM and VLAM.
Dataset
Observation
State
Actions
Task/Instructions
Episodes
Duration (hr)
Size TB
L2D (R4)
RBG (6x)
GPS/IMU/CAN
☑️
☑️
1M
5,000+
90+
Table 4: Open source self-driving datasets. (Source)
releases
Robotics AI models’ performances are bounded by the quality of the episodes within the training set. To ensure the highest quality episodes, we plan a phased release for L2D. With each new release we add additional information about the episodes. Each release R1+ is a superset of the previous releases to ensure clean episode history.
1. instructions: Natural language instruction of the driving task
2. task_id: Mapping of episodes to EU mandated driving tasks (Task ID)
3. observation.state.route : Information about lane count, turn lanes from OSM
4. suboptimal: Natural language description for the sub-optimal policies
HF
Nutron
Date
Episodes
Duration (hr)
Size
instructions
task_id
observation.state.route
suboptimal
R1
R1
April 2025
1K
5+
95 GB
☑️
—
—
—
R2
R2
May 2025
10K
50+
1 TB
☑️
☑️
☑️
☑️
R3
R3
June 2025
100K
500+
10 TB
☑️
☑️
☑️
☑️
R4
R4
July 2025
1M
5,000+
90 TB
☑️
☑️
☑️
☑️
Table 5: L2D release dates (Source)
The entire multimodal dataset collected by Yaak with the driving school fleet is 5x larger than the planned release. To further the growth of L2D beyond R4, we invite the AI community to search and uncover scenarios within our entire data collection and build a community powered open-source L2D. The AI community can now search for episodes through our natural language search and queue their collection for review by the community for merging them into the upcoming releases. With L2D, we hope to unlock an ImageNet moment for spatial intelligence.
Closed Loop Testing
lerobot driver
For real world testing of the AI models trained with L2D and LeRobot, we invite the AI community to submit models for closed loop testing with a safety driver, starting summer of 2025. The AI community will be able to queue their models for closed loop testing, on our fleet and choose the tasks they’d like the model to be evaluated on and, for example, navigating roundabouts or parking. The model would run in inference mode (Jetson AGX or similar) on-board the vehicle. The models will be drive the vehicle with LeRobot driver in two modes
1. drive-by-waypoints: “Follow the waypoints adhering to driving rules and regulations” given observation.state.vehicle.waypoints
2. drive-by-language: “Drive straight and turn right at the pedestrian crossing”
additional resources
Driving task catalog (Fahraufgabenkatalog)
appendix
A.1 Route Tasks
List of route restrictions. We consider route tags from OSM a restriction if it imposes restrictions on the policy, for example speed limit, yield or construction. Route features are physical structures along the route, for example inclines, tunnels and pedestrian crossing. Route maneuvers are different scenarios which a driver encounters during a normal operation of the vehicle in an urban environment, for example, multilane left turns and roundabouts.
Type
Name
Assignment
Task ID
Release
Route restriction
CONSTRUCTION
VLM
—
R1
Route restriction
CROSS_TRAFFIC
VLM
4.3.1.3a
4.3.1.3b
4.3.1.3d
4.2.1.3a
4.2.1.3b
4.2.1.3d
R2
Route restriction
INCOMING_TRAFFIC
VLM
—
R2
Route restriction
PEDESTRIANS
VLM
7.2.1.3b
R1
Route feature
CURVED_ROAD
OSM (derived)
2.1.1.3a,
2.1.1.3b
R0
Route feature
NARROW_ROAD
VLM
—
—
Route feature
PARKING
OSM
—
R0
Route maneuver
ENTERING_MOVING_TRAFFIC
OSM (derived)
4.4.1.3a
R0
Route maneuver
CUTIN
VLM
—
R3
Route maneuver
LANE_CHANGE
VLM
1.3.1.3a,
1.3.1.3b
R3
Route maneuver
PROTECTED_LEFT
OSM (derived)
4.3.1.3c,
4.3.1.3d
R0
Route maneuver
PROTECTED_RIGHT_WITH_BIKE
OSM (derived)
4.2.1.3c,
4.2.1.3d
R0
Route maneuver
RIGHT_BEFORE_LEFT
OSM (derived)
4.1.1.3a,
4.2.1.3a,
4.3.1.3a,
R0
Route maneuver
STRAIGHT
OSM (derived)
8.1.1.3a
R0
Route maneuver
OVER_TAKE
VLM
3.2.1.3a,
3.2.1.3b
R4
Route maneuver
UNPROTECTED_LEFT
OSM (derived)
4.3.1.3a,
4.3.1.3b
R0
OSM = Openstreetmap, VLM= Vision Language Model, derived: Hand crafted rules with OSM data
A.2 llm prompts
Prompt template and pseudo code for configuring the LLM using groq to parse natural language queries into structured prediction for route features, restrictions and maneuvers with a pydantic model. The natural language queries are constructed to closely follow the turn-by-turn navigation available in most GPS navigation devices.
Example pairs (showing 3 / 30) for in-context learning to steer the structured prediction of LLM, where ParsedInstructionModel is a pydantic model.
A.3 data collection hardware

Onboard compute: NVIDIA Jetson AGX Xavier
8 cores @ 2/2.2 GHz, 16/64 GB DDR5
100 TOPS , 8 lanes MIPI CSI-2 D-PHY 2.1 (up to 20Gbps)
8x 1080p30 video encoder (H.265)
Power: 10-15V DC input, ~90W power consumption
Storage: SSD M.2 (4gen PCIe 1x4)
Video input 8 cameras:
2x Fakra MATE-AX with 4x GMSL2 with Power-over-Coax support
Onboard compute: Connectivity
Multi-band, Centimeter-level accuracy RTK module
5G connectivity: M.2 USB3 module with maximum downlink rates of 3.5Gbps and uplink rates of 900Mbps, dual SIM
Component
#
Vendor
Specs